先接上旧知识:和 Pixel Recursive SR 有何不同?
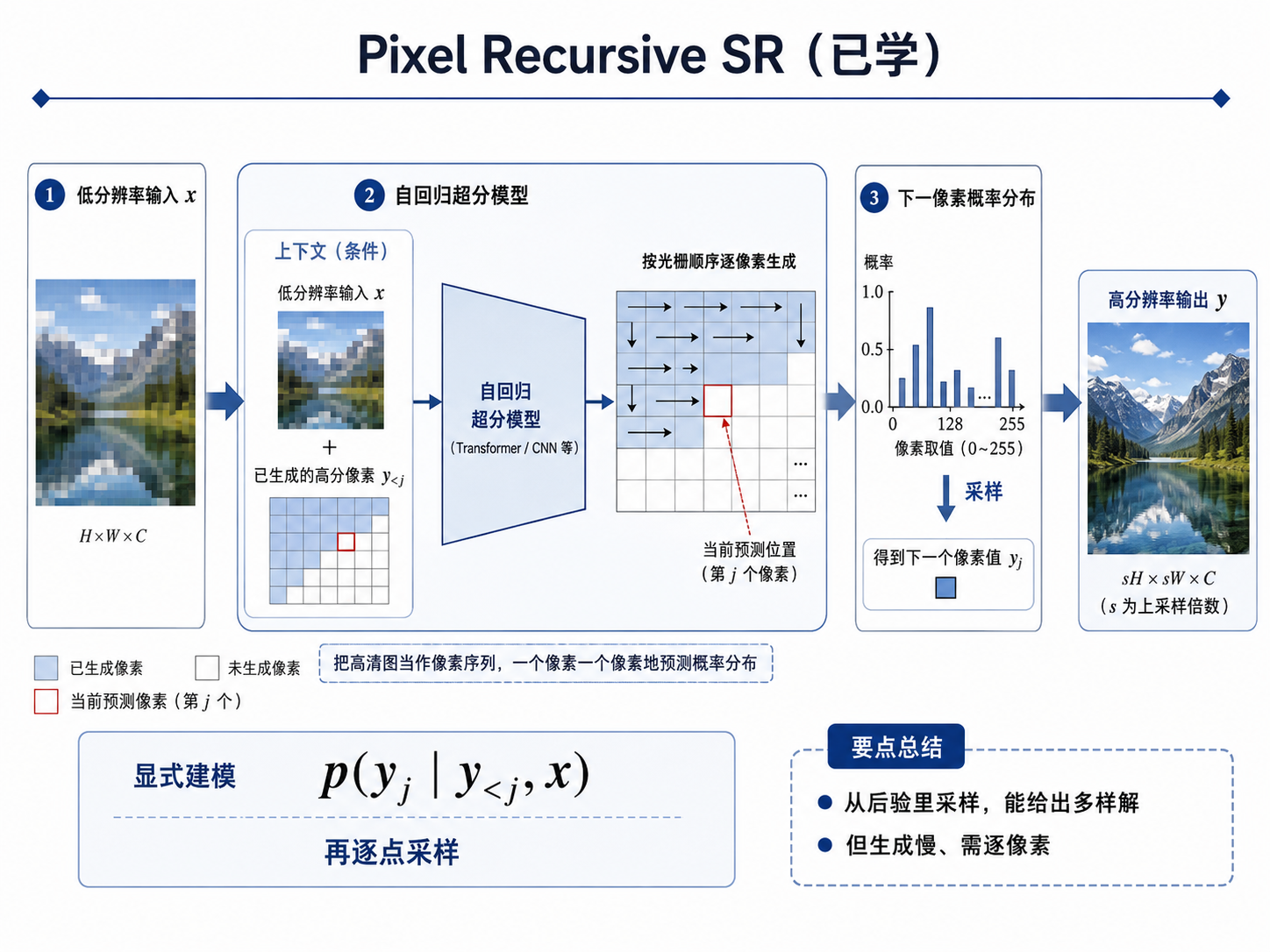
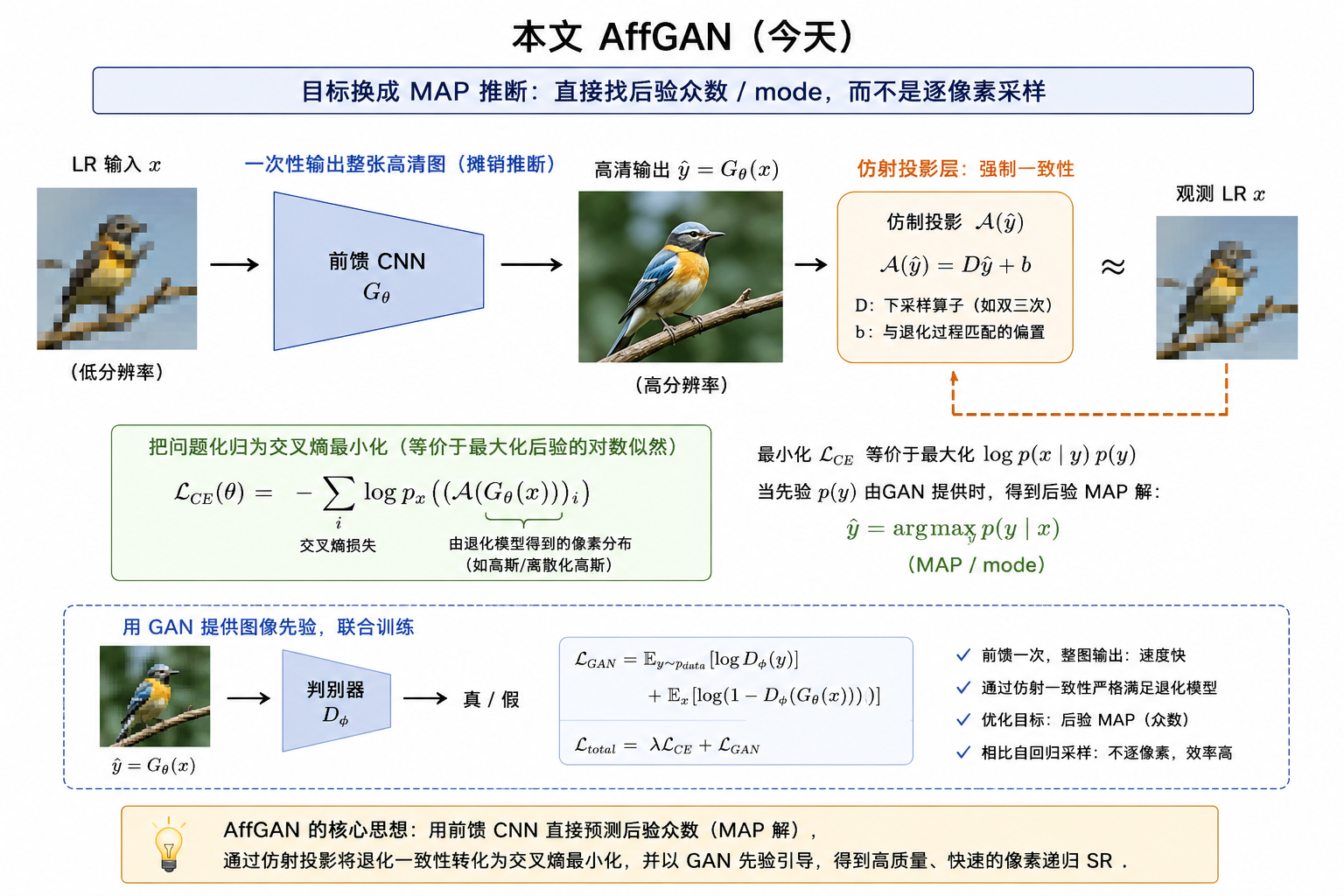
一句话区别 ▸ 两者都在和"图像先验/概率分布"打交道;但 PRSR 显式建模分布并采样,AffGAN 不显式建分布,而是把找众数变成训练一个生成器。论文 §5.6 还反过来讨论"何时该改用采样"——与 PRSR 殊途同归。
AffGAN · 用于图像超分辨率的摊销 MAP 推断04
先问一句:什么是"点估计 point estimation"?
贝叶斯给我们的是一整条分布,但最终只能输出一张确定的图——必须从分布里挑一个"代表点"。
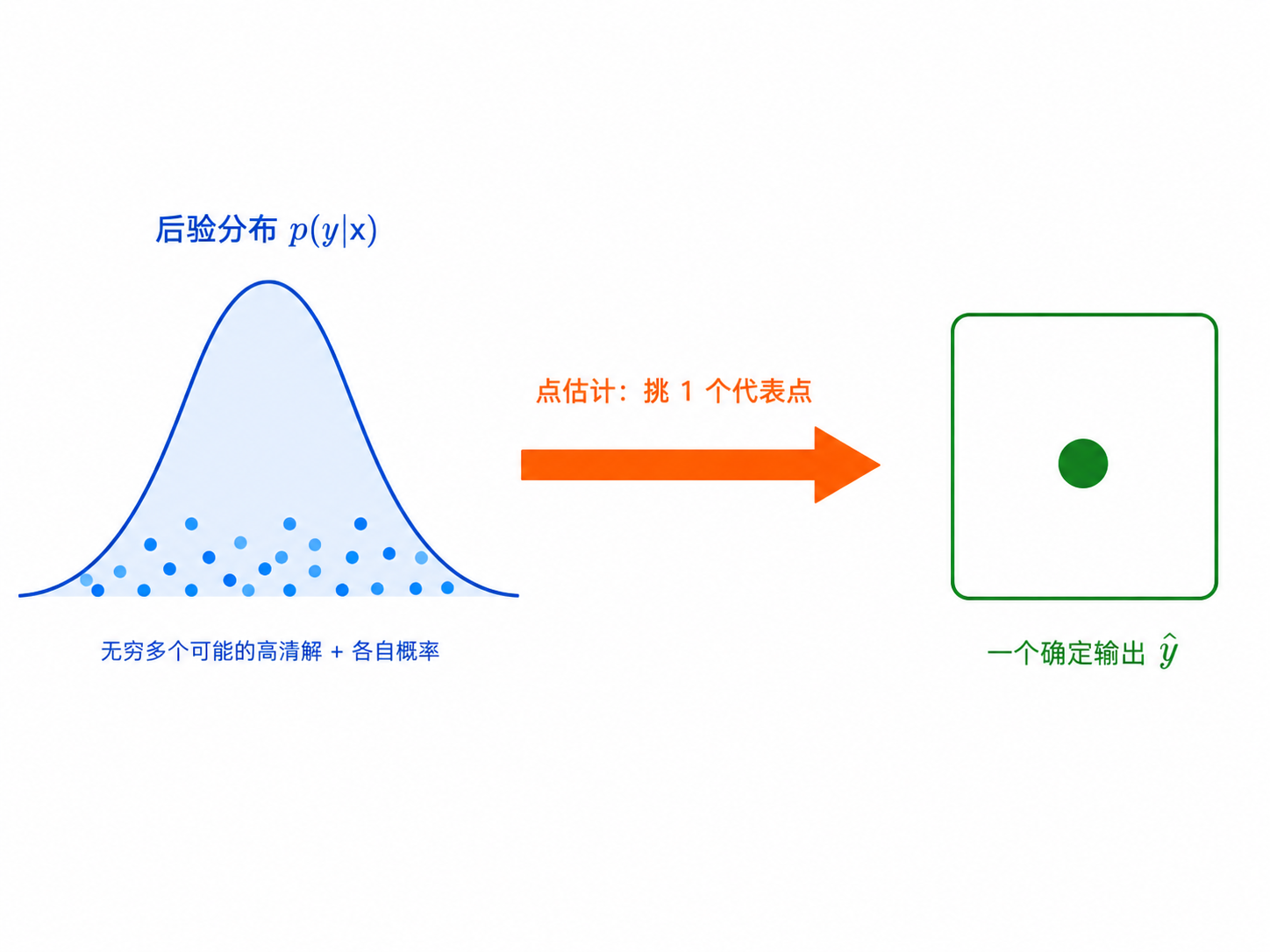
- 完整贝叶斯:给出整条后验 p(y|x)——所有可能解 + 各自概率
- 但落地要一个确定输出 → 用单个值/向量去概括整条分布,这就是 点估计
- "挑哪个点"有不同策略 → 下一页的 均值 / 中位数 / 众数
和 PRSR 对照 ▸ PRSR 直接采样整条分布、给多样解;本文走点估计,只取一个代表点(MAP)。两条路在 §5.6 又会重新交汇。
AffGAN · 何为点估计05
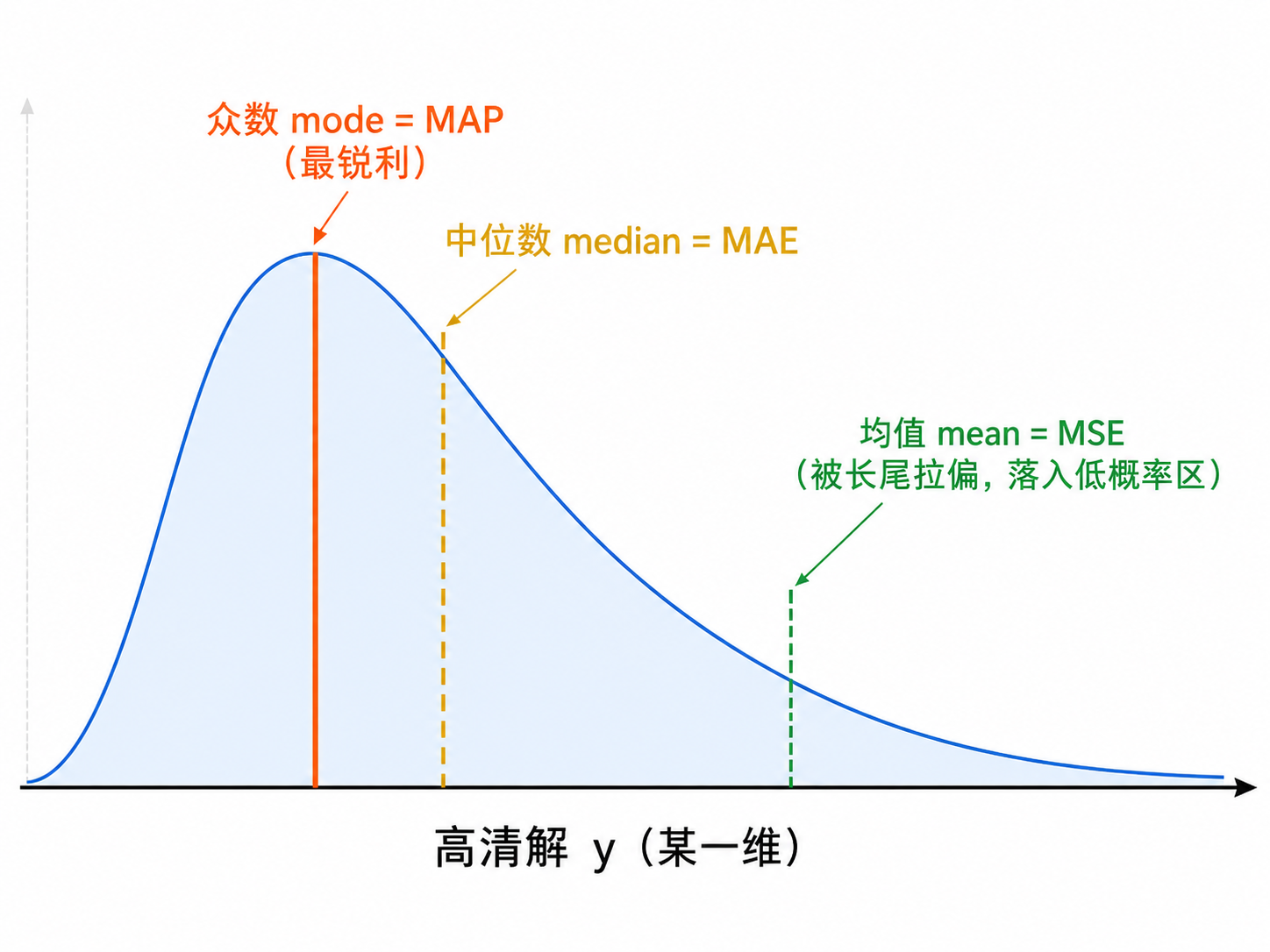
点估计"三兄弟":均值 mean / 中位数 median / 众数 mode
同一条后验分布 posterior p(y|x),你选的损失函数不同,"贝叶斯最优答案"就落在不同位置。
| 损失函数 Loss | 贝叶斯最优解 | 特点 |
|---|---|---|
| 平方损失 · MSE | 后验均值 mean | 易糊 |
| 绝对损失 · MAE | 后验中位数 median | 较稳健 |
| 0–1 损失 | 后验众数 mode = MAP | 最锐利 |
关键 ▸ 三者都是合法的"最优解",差别只在损失函数。SR 里多个解并存:均值把它们抹平→糊;中位数稍好;只有众数 mode 落在概率最高处→最锐利、最可信。这正是本文选 MAP 的理由。
MAP
Maximum a Posteriori · 最大后验
argmaxy p(y|x),取后验最大的点(= 众数 mode)。本文的目标。
MLE
Maximum Likelihood Estimation · 最大似然
只看似然 p(x|y)、不含先验;= 无信息先验下的 MAP。
后验 Posterior
posterior ∝ likelihood × prior
p(y|x) ∝ p(x|y) · p(y)。MAP 就在它上面取峰值。
mode / mean / median
众数 / 均值 / 中位数
分布的"峰值 / 重心 / 中点",分别是 MAP / MSE / MAE 的最优解。
AffGAN · 扫盲:点估计06
不是"唯一还原",而是在满足约束的候选里挑最像真实分布的点
低清 x 给的不是答案,而是一个约束;好解还要落在真实图像分布的高概率区。
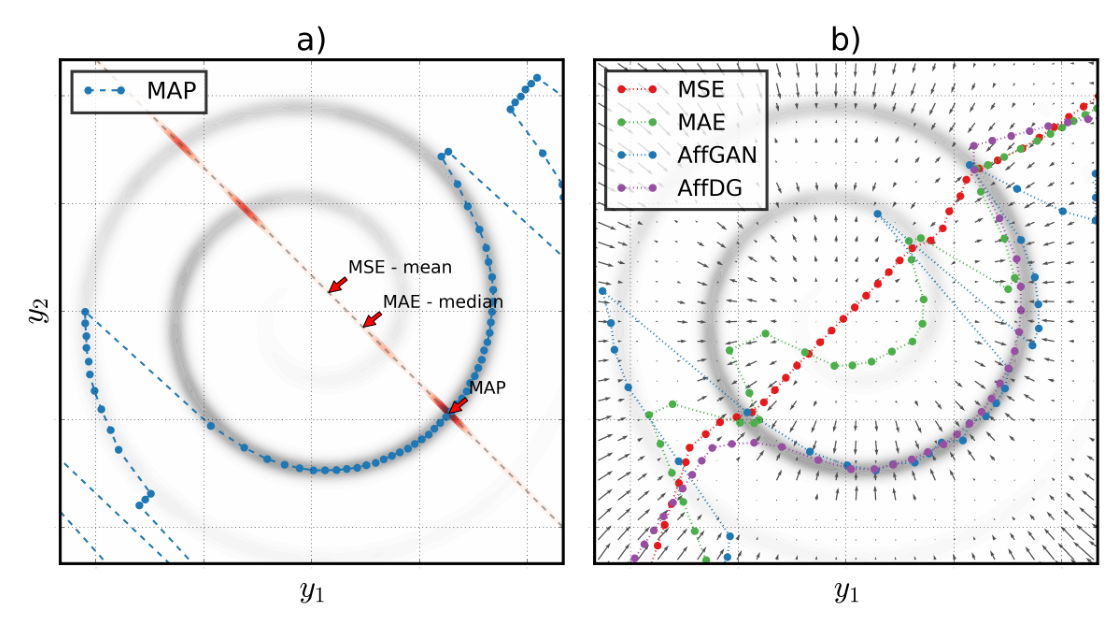
注意:图中彩色点是各方法对不同 x 的 SR 输出,不是瑞士卷数据点——图 a 蓝点 = MAP;图 b 红 = MSE/绿 = MAE/蓝 = AffGAN/紫 = AffDG(同是蓝点,a 是 MAP、b 是 AffGAN)。
① 约束:Ay=x → 橙线
→
② 后验:先验沿橙线切片
→
③ 选点:mean / median / mode
→
④ 结果:Table 1
Table 1 · 直接估计的交叉熵(10 次随机初始化平均)
| 方法 | \( H[q_\theta,p_Y] \) 越低越像真实 | \( \ell_{\mathrm{MSE}}(x,A\hat y) \) 一致性 |
|---|---|---|
| MAP(暴力解) | 3.15 | — |
| MSE | 9.10 | 1.25·10⁻² |
| MAE | 6.30 | 4.04·10⁻² |
| AffGAN | 4.10 | 0.0 |
| SoftGAN | 4.25 | 8.87·10⁻² |
| AffDG | 3.81 | 0.0 |
| SoftDG | 4.19 | 1.01·10⁻¹ |
读表 ▸ AffGAN/AffDG 的交叉熵 ≈ MAP(3.15)→ 确实落在高概率区;MSE 9.10、MAE 6.30 明显跑偏。一致性 \( \ell_{\mathrm{MSE}} \):Aff(投影)= 0 严格满足,Soft(软约束)≠ 0。
AffGAN · Figure 1 + Table 107
什么是"摊销 MAP 推断"?传统 MAP vs 摊销 MAP
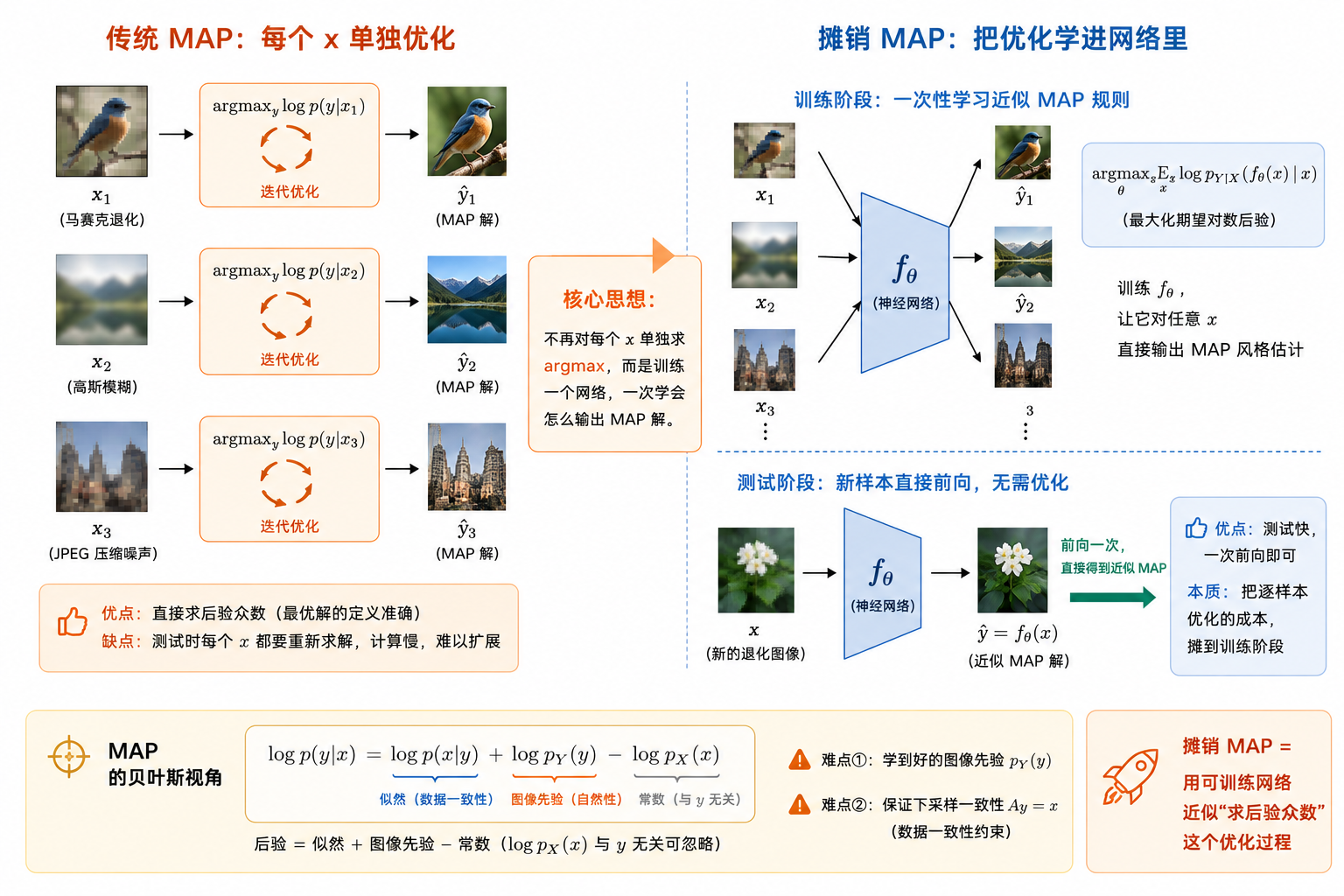
一句话 ▸ 摊销 = 不再对每个 x 单独求 argmax,而是训练一个网络一次学会输出 MAP 解,测试时前向一次直接出图。贝叶斯分解 \( \log p(y|x)=\log p(x|y)+\log p_Y(y)-\log p_X(x) \):后验 = 似然 + 图像先验 − 常数;难点在图像先验 pY 与一致性约束 Ay=x(本部分逐一展开)。
AffGAN · 摊销 MAP 推断10
三个词先讲清:列空间 · 零空间 · 伪逆
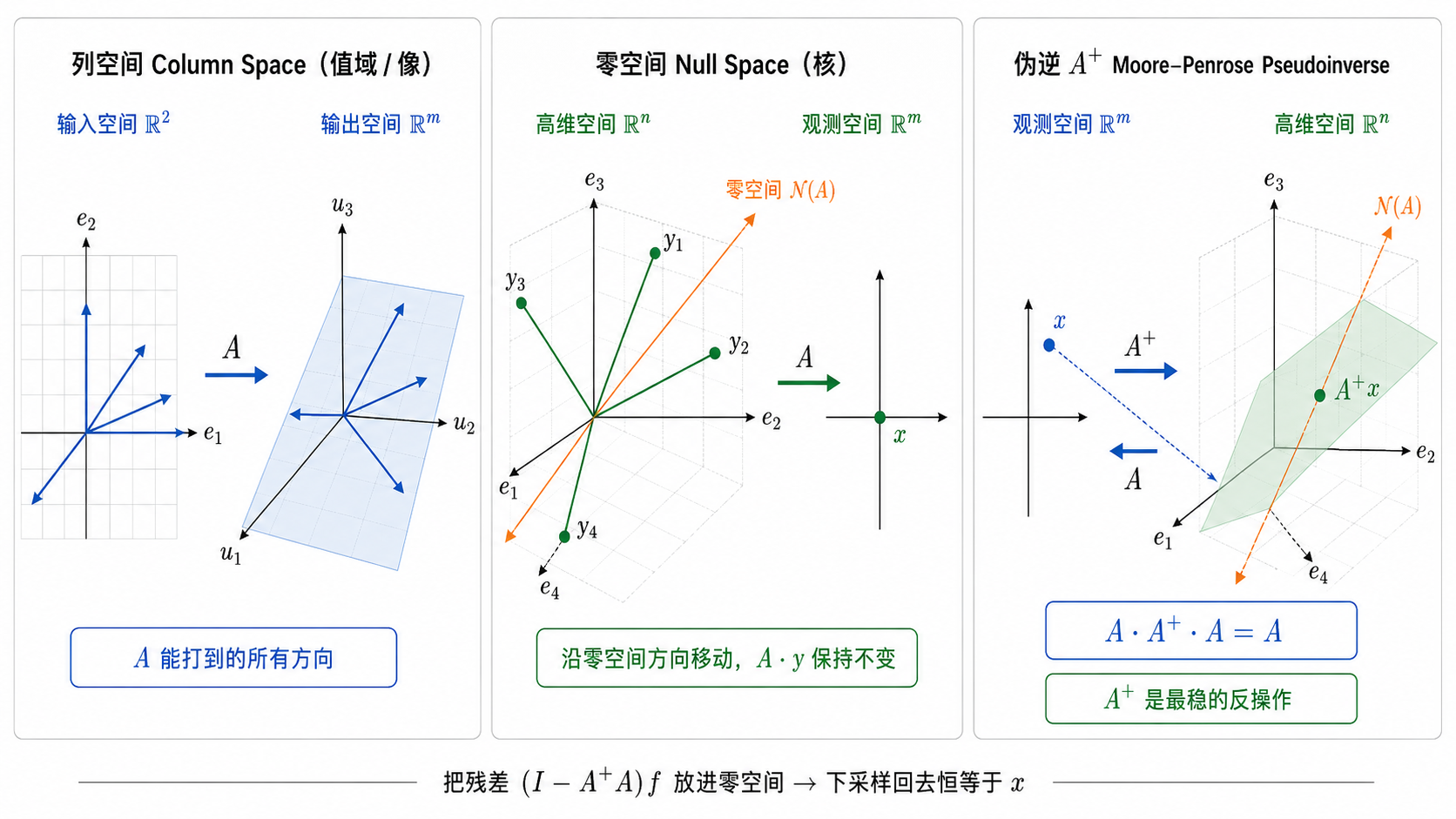
- 列空间 Column Space(像 / 值域):矩阵 A 能"打到"的所有方向
- 零空间 Null Space(核):被 A 压成 0 的方向 —— 沿它走,下采样结果不变
- 伪逆 A⁺(Moore–Penrose Pseudoinverse):最稳的"反操作",满足 A A⁺A = A
把残差 (I − A⁺A)f 放进零空间,无论 f 输出啥,下采样回去恒等于 x。这就是下一页"一致性被结构强制"的几何根源。
AffGAN · 扫盲:线性代数11
本文最硬核的创新:仿射投影层
\[ g_\theta(x)=\textcolor{#1a4f8a}{\Pi_x^{A}}\,f_\theta(x)=\textcolor{#2f8a5b}{(I-A^{+}A)\,f_\theta(x)}+\textcolor{#1a4f8a}{A^{+}x} \]
残差:落在 A 的零空间,下采样恒为 0 | 基线解:把 LR 直接上采样,保证低频正确
- 输出经下采样精确还原 x —— 一致性被结构强制,而非靠损失软性鼓励
- A⁺ 是反卷积/上卷积,深度学习标准操作(注意 A⁺ ≠ Aᵀ)
- 可插到任何 CNN 甚至任何可训练 SR 算法之后
为何重要 ▸ 有了它,约束优化 → 无约束优化,MAP 目标才能进一步化归成"交叉熵最小化"(下一页)。
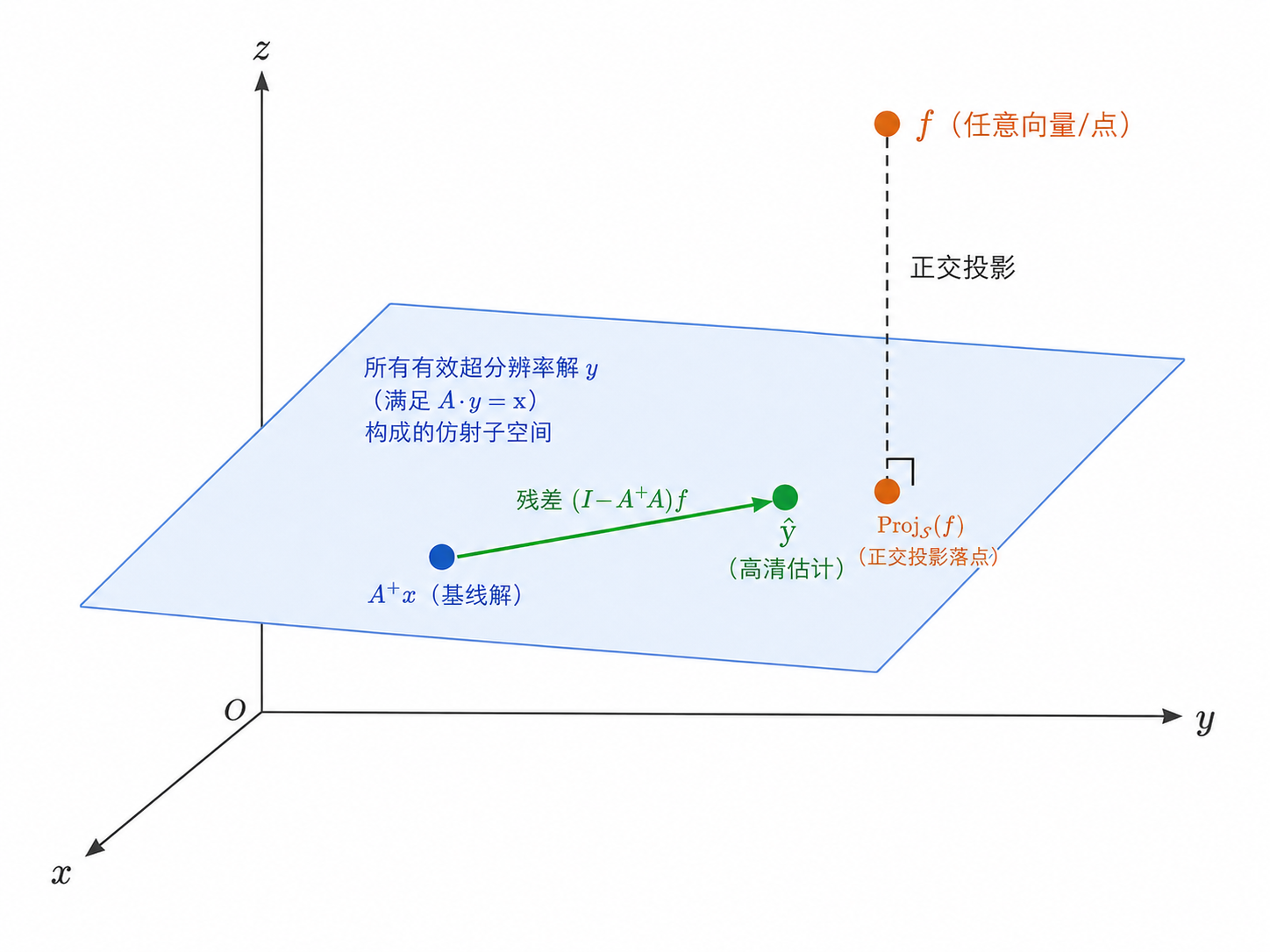
AffGAN · 仿射投影层12
熵 / 交叉熵 / KL:用"编码花几个 bit"来记
用"发送消息要花多少 bit"的直观物理视角,理清这三个概念的数学关系与几何桥梁。
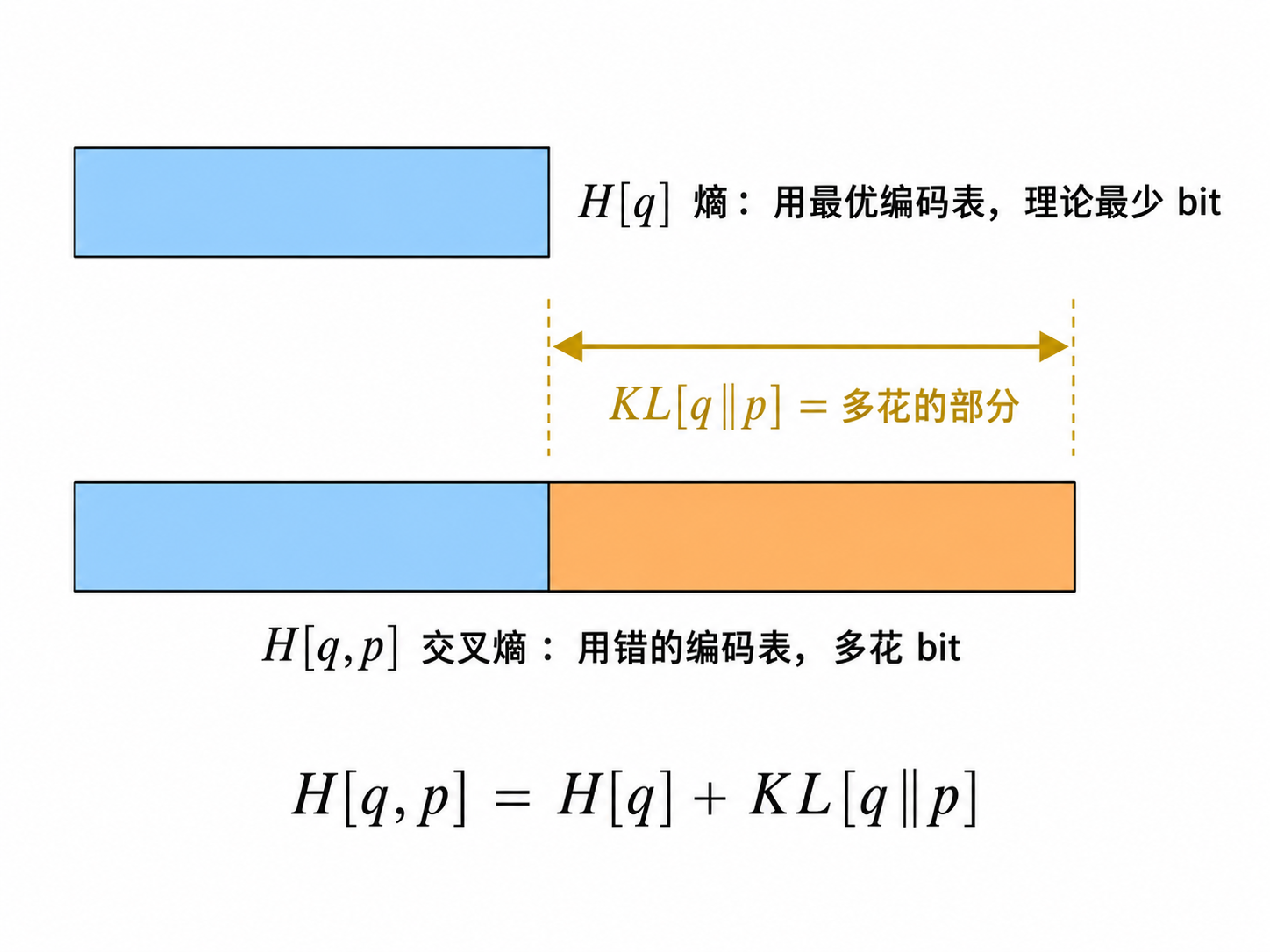
\[ H[q,p]=H[q]+\mathrm{KL}[q\,\|\,p] \]
交叉熵 = 自身熵 + KL 散度
核心推论 ▸ 恒等式 H[q,p] − KL[q‖p] = H[q] 后面会立大功:
• 在最大似然估计(MLE)中,是以真实分布为基准,故最小化交叉熵 ⟺ 最小化 KL 散度;
• 但在本文的 MAP 目标中,第一项是模型诱导分布 qθ,其自身熵并不固定。GAN 实际最小化的 KL 散度与我们想最小化的交叉熵正好差了一个 H[qθ](即"熵奖励",详见第 18 页)。
• 在最大似然估计(MLE)中,是以真实分布为基准,故最小化交叉熵 ⟺ 最小化 KL 散度;
• 但在本文的 MAP 目标中,第一项是模型诱导分布 qθ,其自身熵并不固定。GAN 实际最小化的 KL 散度与我们想最小化的交叉熵正好差了一个 H[qθ](即"熵奖励",详见第 18 页)。
熵 H[q]
最优编码长度 · Entropy
用基于 q 自身定制的最优编码表,理论上发送 q 分布的消息平均最少需要花的 bit 数。
交叉熵 H[q,p]
错配编码长度 · Cross Entropy
实际符号分布是 q,却错用 p 的编码表来发送消息,导致每个符号平均需要多花的实际 bit 数。
KL 散度 KL[q‖p]
冗余开销/溢价 · KL Divergence
因为错用 p 的编码表而多花的那部分 bit(即 H[q,p] − H[q]),衡量两个分布的差异。
AffGAN · 扫盲:信息论14
GAN 基础我们学过——这里怎么用?与 SRGAN 差在哪?
30 秒回顾(已知)
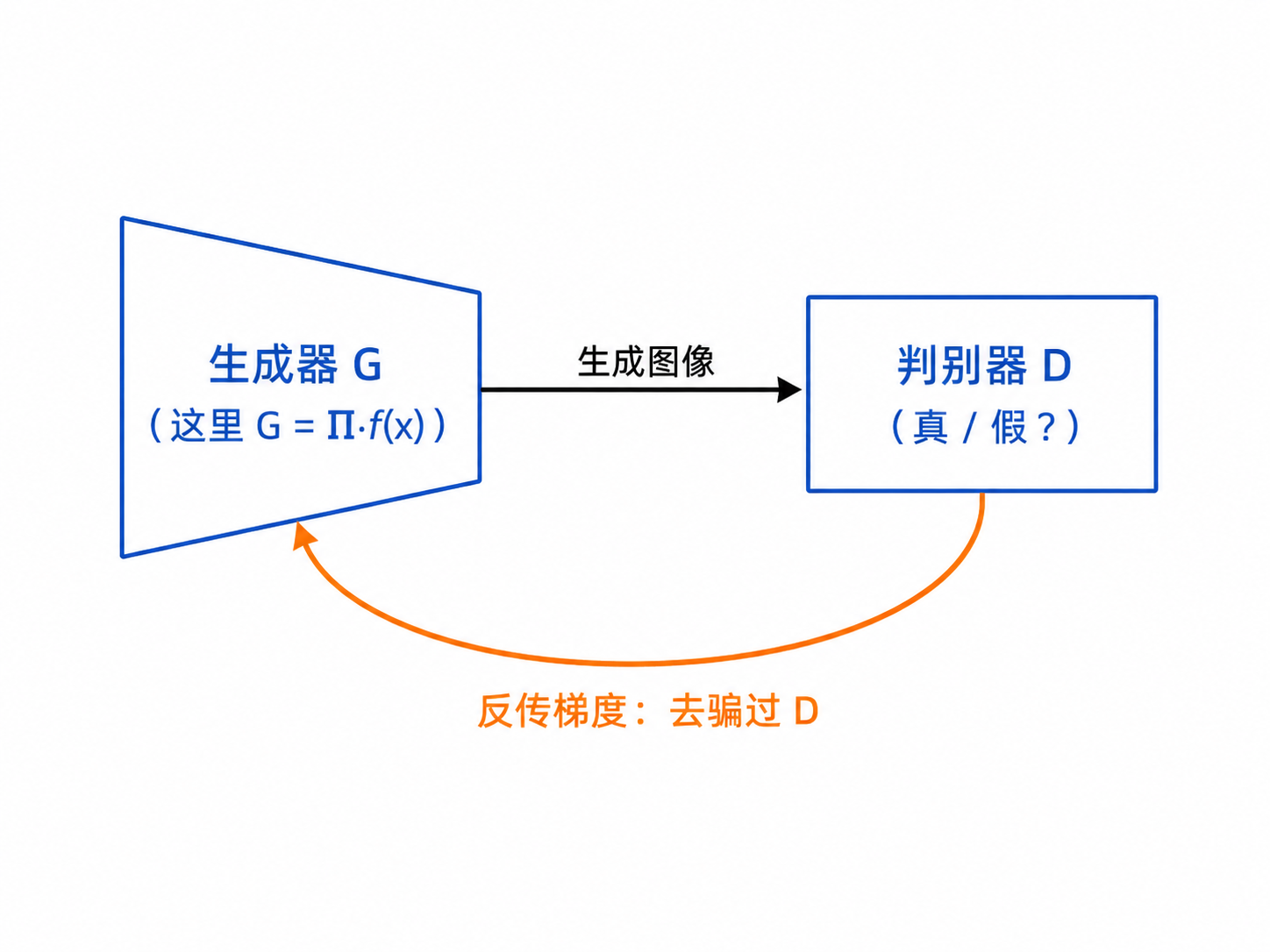
本文两处改造:① 生成器输入不是噪声 z,而是低清图 x;② 用修正的生成器更新规则,使 GAN 不再最小化 JS,而是 KL[qθ‖pY](≈ 交叉熵 = MAP)。
| 维度 | SRGAN(Ledig 2016) | 本文 AffGAN |
|---|---|---|
| 一致性 Aŷ=x | 软约束:靠内容/MSE 损失"鼓励" | 仿射投影硬保证(误差≈0) |
| 损失构成 | 对抗损失 + VGG 感知损失 + MSE | 纯对抗(修正规则),无需 VGG/内容损失 |
| 训练数据 | 必须成对 LR–HR | 原则上只需 pY、pX 的样本 |
| 理论解释 | 经验性、效果驱动 | GAN=最小化 KL/交叉熵=MAP 推断(附录 A) |
| 观测噪声假设 | 隐含高斯/拉普拉斯 | 不假设,精确满足观测模型 |
| 稳定化技巧 | 常规 GAN trick | 实例噪声(退火,不引入偏差) |
一句话 ▸ SRGAN 是"把 GAN 当感知损失加进 SR";AffGAN 是"把整个 SR 重新推导成 GAN"——并证明这等价于 MAP 推断。本文为 SRGAN 那条经验路线补上了理论依据。
AffGAN · GAN 的运用 vs SRGAN16
AffGAN:把仿射投影的 SR 函数当作生成器
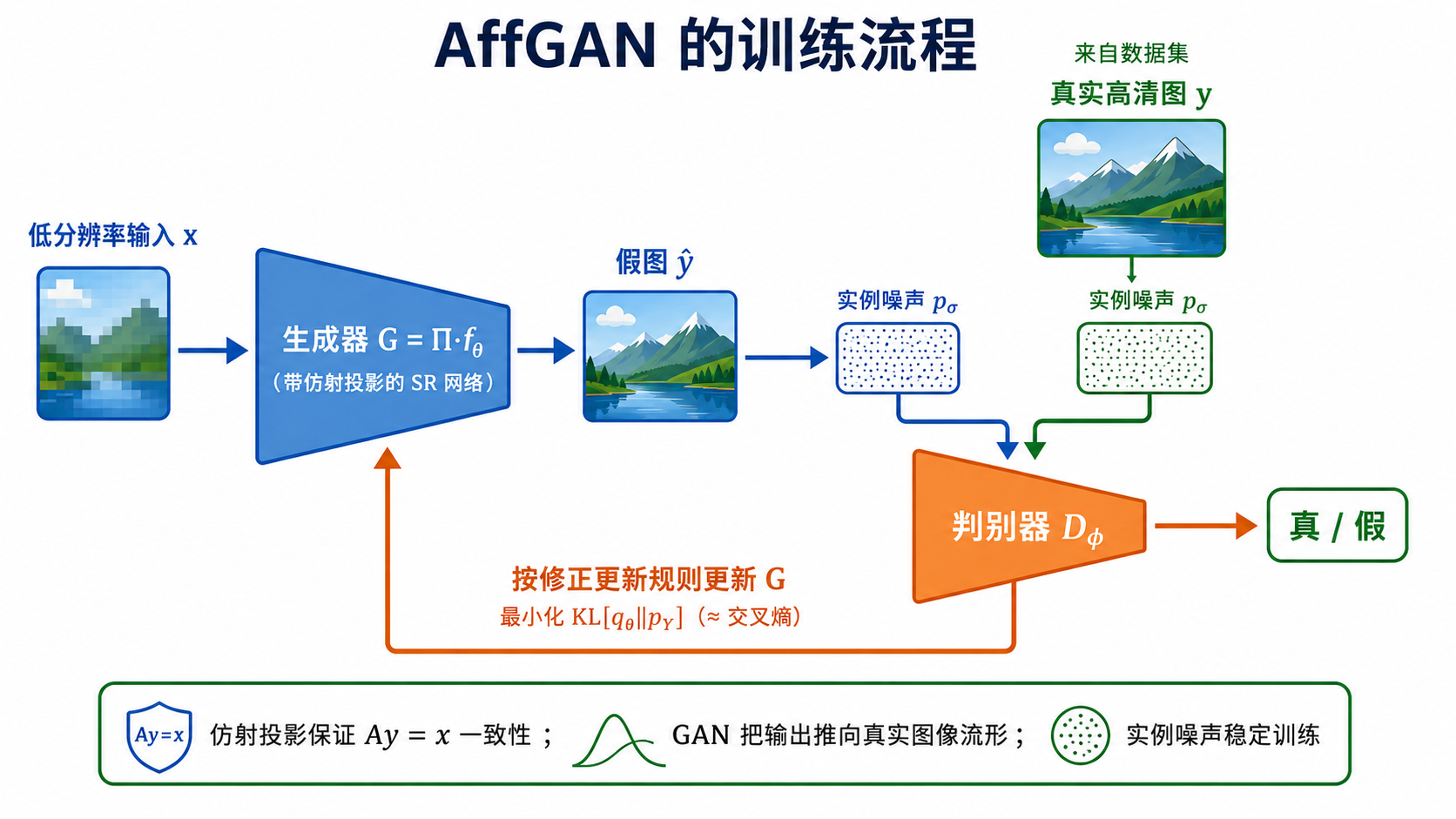
为什么“投影+GAN”天作之合 ▸ 投影负责一致性(Aŷ=x 恒成立),GAN 负责把输出推向真实图像流形;不需成对数据、不假设观测噪声。对照组 SoftGAN=去掉投影、改软约束 ℓLR=MAE(x,Aŷ)。这为“GAN 用于 SR”(SRGAN)补上了理论依据。
AffGAN · 方法一17
GAN 为何不稳定?实例噪声来救场
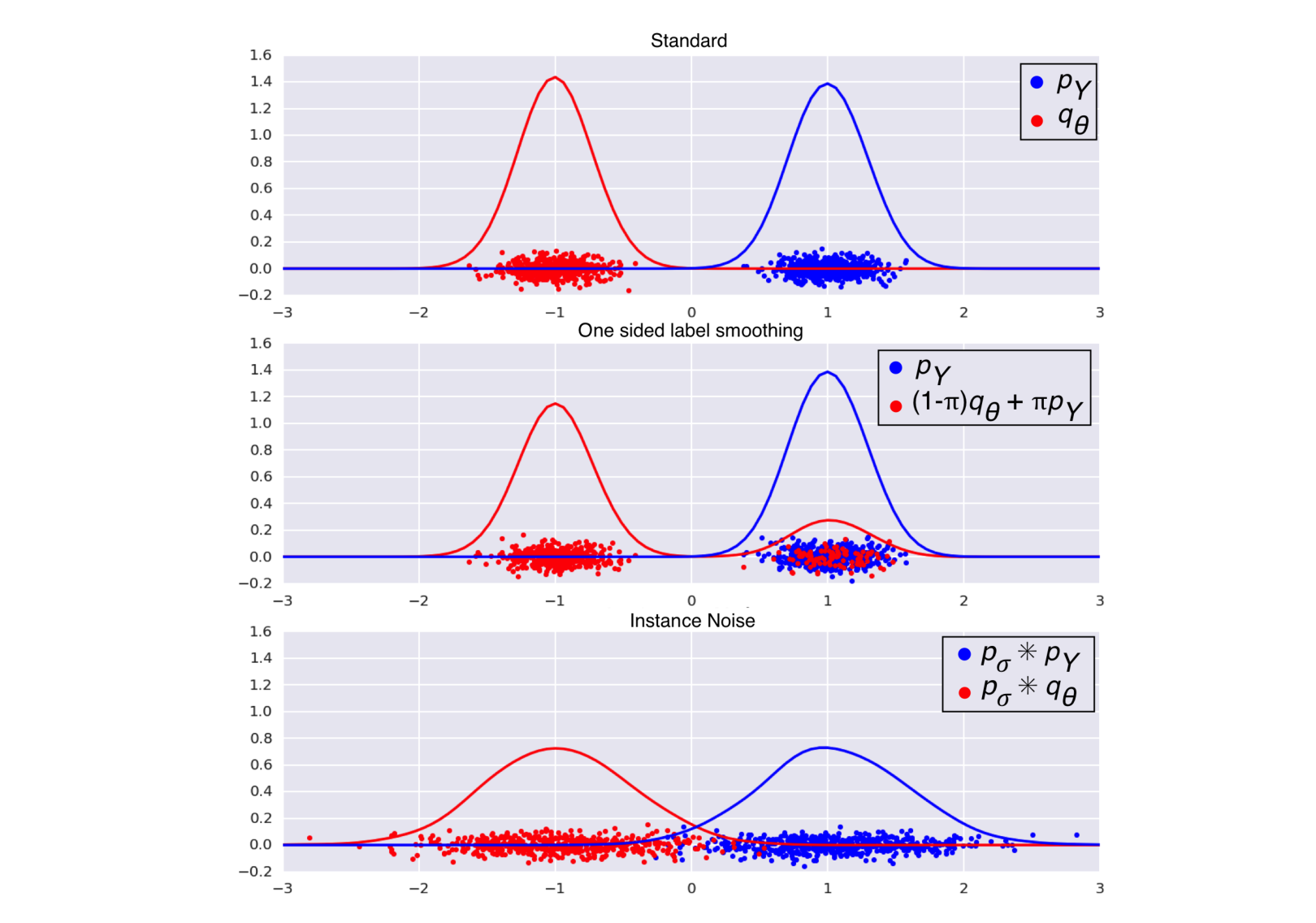
病因:pY 与 qθ 都是高度集中、支撑集几乎不重叠的分布 → 存在一大批"近似最优判别器",每个给 G 的梯度都不同 → 训练发散。
\[ d_\sigma=\mathrm{KL}[\,p_\sigma \ast q_\theta\,\|\,p_\sigma \ast p_Y\,] \]
给真假样本都加高斯噪声,σ 随训练退火到 0
类比 ▸ 两条几乎不重叠的细线,判别器能用无数种方式分开它们;给两条线都"吹"一层高斯噪声,它们变胖、重叠,最优判别器变唯一、梯度稳定。优于单边标签平滑(不引入偏差)。
AffGAN · 实例噪声19
一个关键洞见:去噪 = 学习对数密度的梯度
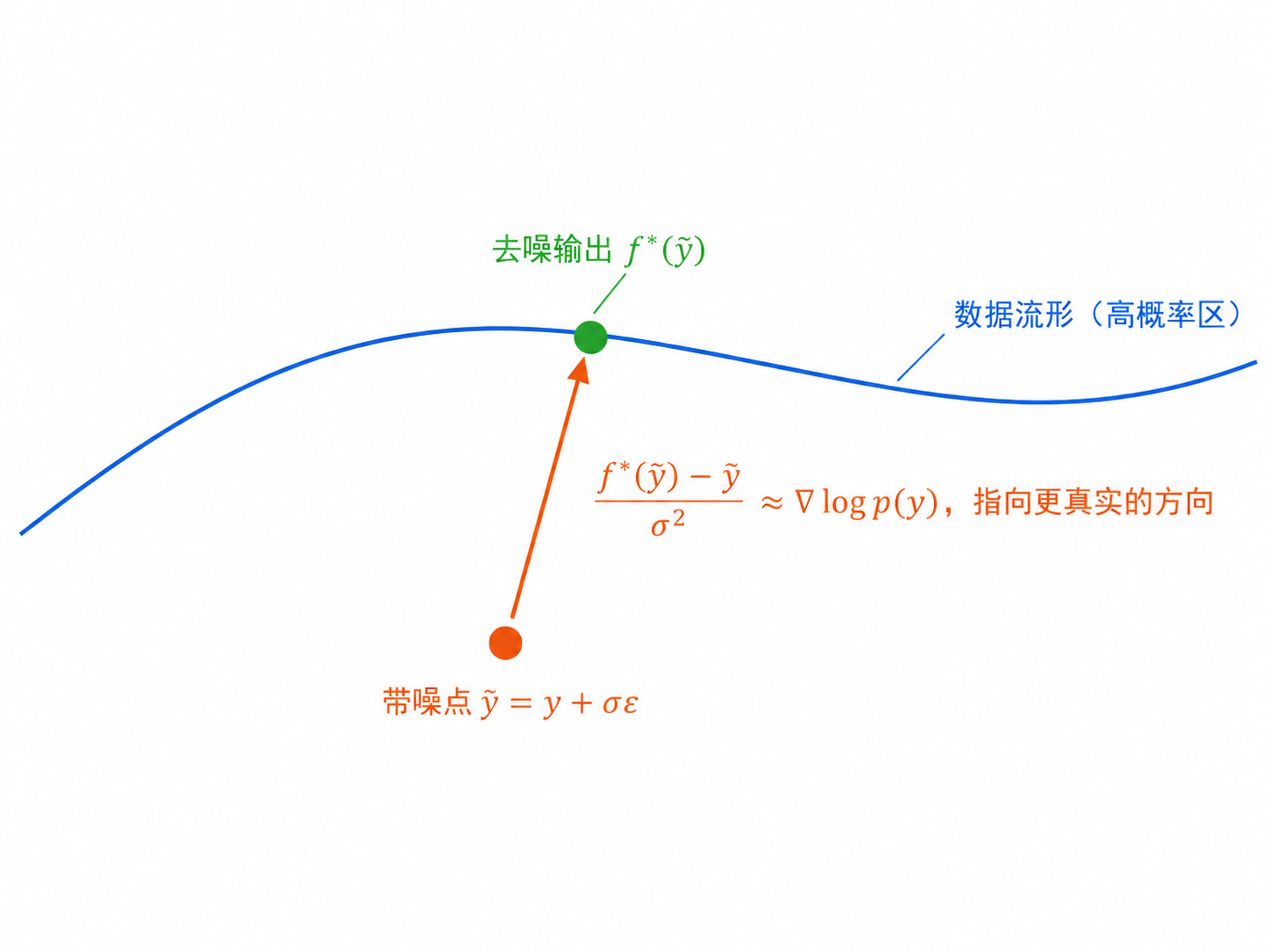
\[ \frac{f^{*}(y)-y}{\sigma^{2}}\;\approx\;\nabla_{y}\log p_Y(y) \]
贝叶斯最优去噪器隐含了对数密度的梯度(式 12)
- 训练一个去噪器,"去噪输出 − 带噪输入"就近似指向 ∇ log pY
- 于是无需显式知道先验 pY,也能拿到"往更真实方向走"的梯度
- 正是当今扩散模型 / score matching 的同源思想(Vincent 2011)
AffGAN · 扫盲:去噪=梯度20
AffDG:用去噪器的梯度反传训练 SR 网络
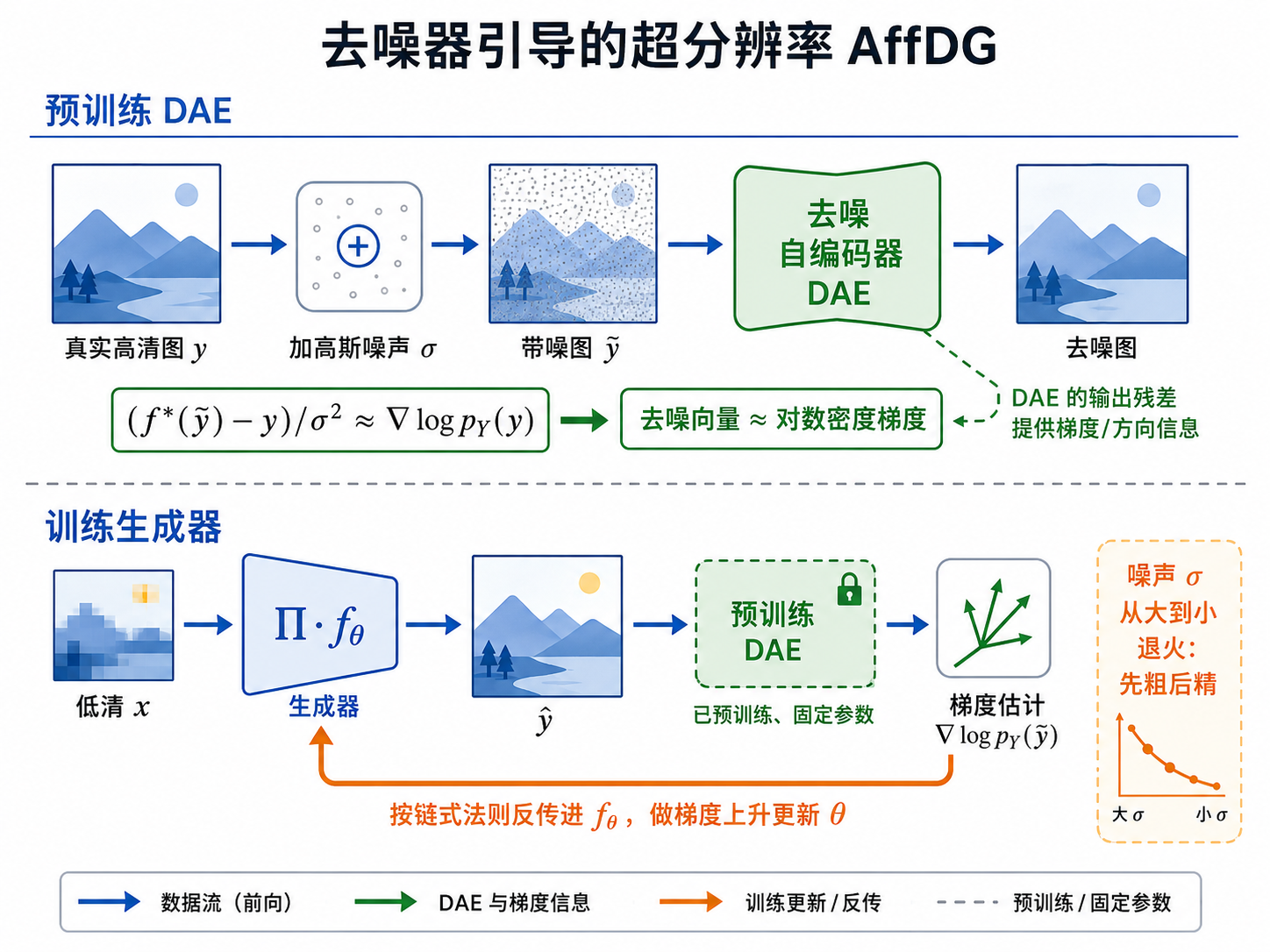
训练技巧 ▸ 噪声 σ 从大到小退火:早期梯度方向粗但覆盖广,后期贴近数据流形更精确。对照组 SoftDG=去投影。据作者所知,这是首次把去噪器输出显式反传去训练另一个网络。
AffGAN · 方法二 AffDG21
概念验证:仿射投影不会损害 SR 性能
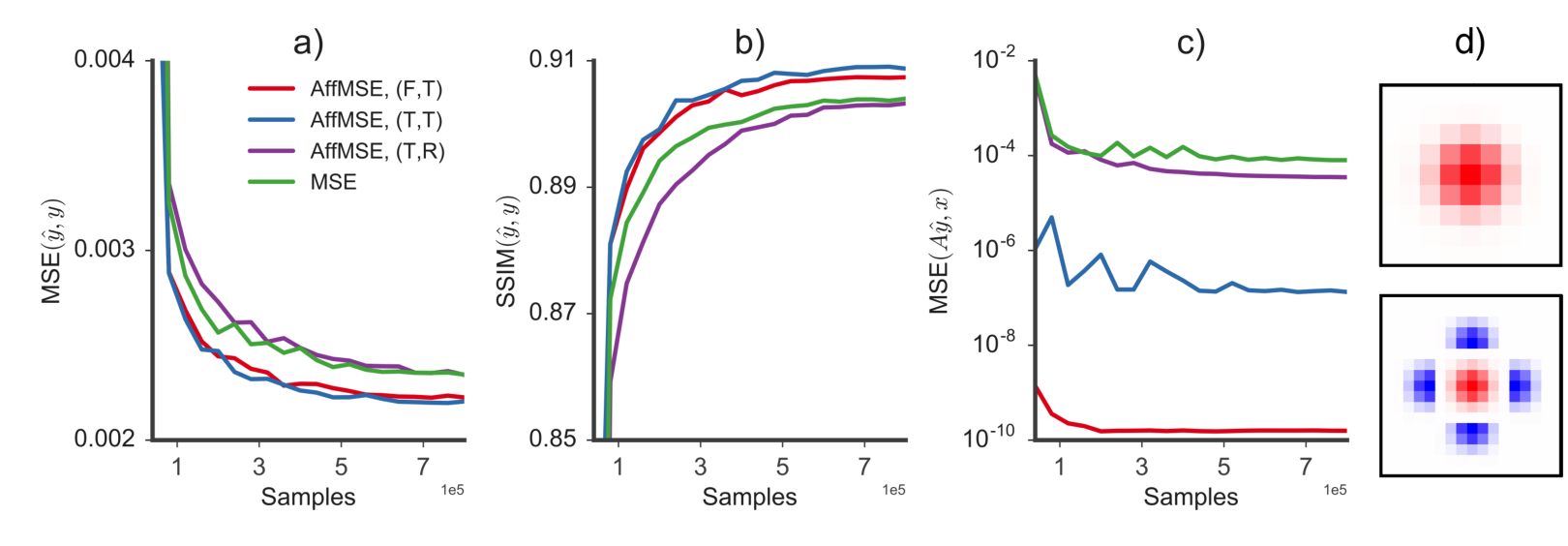
- 带投影的网络初始损失更低(低频已对齐)、训练更快
- 以 MSE / SSIM 衡量,往往还能找到更好的解(a, b)
- 关键:A⁺ 要初始化成正确的伪逆;固定或可训练都行
- (c) 精确投影把一致性误差压到≈ 0(数值精度内)
结论 ▸ 给架构加这个约束有百利而无一害——既保证一致性,又不牺牲(反而常提升)性能。
AffGAN · 实验:仿射投影25
草地纹理 4×:AffGAN 最锐利

看点 ▸ AffGAN 显著比略糊的 AffMSE 锐利。重建并非逐像素完美,但统计属性正确,人眼一看就是草。
对照 ▸ AffDG 与 AffLL 都很模糊(多种优化都救不回来)→ 作者据此聚焦 AffGAN,其余放进附录 E。
AffGAN · 实验:草地纹理26
CelebA 人脸 4×:锐利度 vs PSNR 的权衡

| SSIM | PSNR | Aŷ↔x | |
|---|---|---|---|
| MSE | 0.90 | 26.30 | 8·10⁻⁵ |
| AffMSE | 0.91 | 26.53 | 1.6·10⁻¹⁰ |
| SoftGAN | 0.76 | 21.11 | 2.3·10⁻³ |
| AffGAN | 0.81 | 23.02 | 9.1·10⁻¹⁰ |
要点 ▸ PSNR/SSIM 上 MSE 反而最高——再次说明这些指标偏爱模糊。但人眼更爱 AffGAN。一致性上 Aff ≫ Soft。
AffGAN · 实验:CelebA27
ImageNet 自然图像:AffGAN 会"梦出"合理细节

- 大多数图像锐利、与 LR 输入对应良好
- 仍带有 GAN 常见的高频噪声,与真值可区分
趣点 ▸ 第三列:蛇被超分成了"水"——显然错误,但在图像先验下"水"概率更高,说明 GAN 在"梦出"合理数据。这恰是 MAP/生成式方法的特性。
AffGAN · 实验:ImageNet28
冷静一下:高维下"众数未必典型"
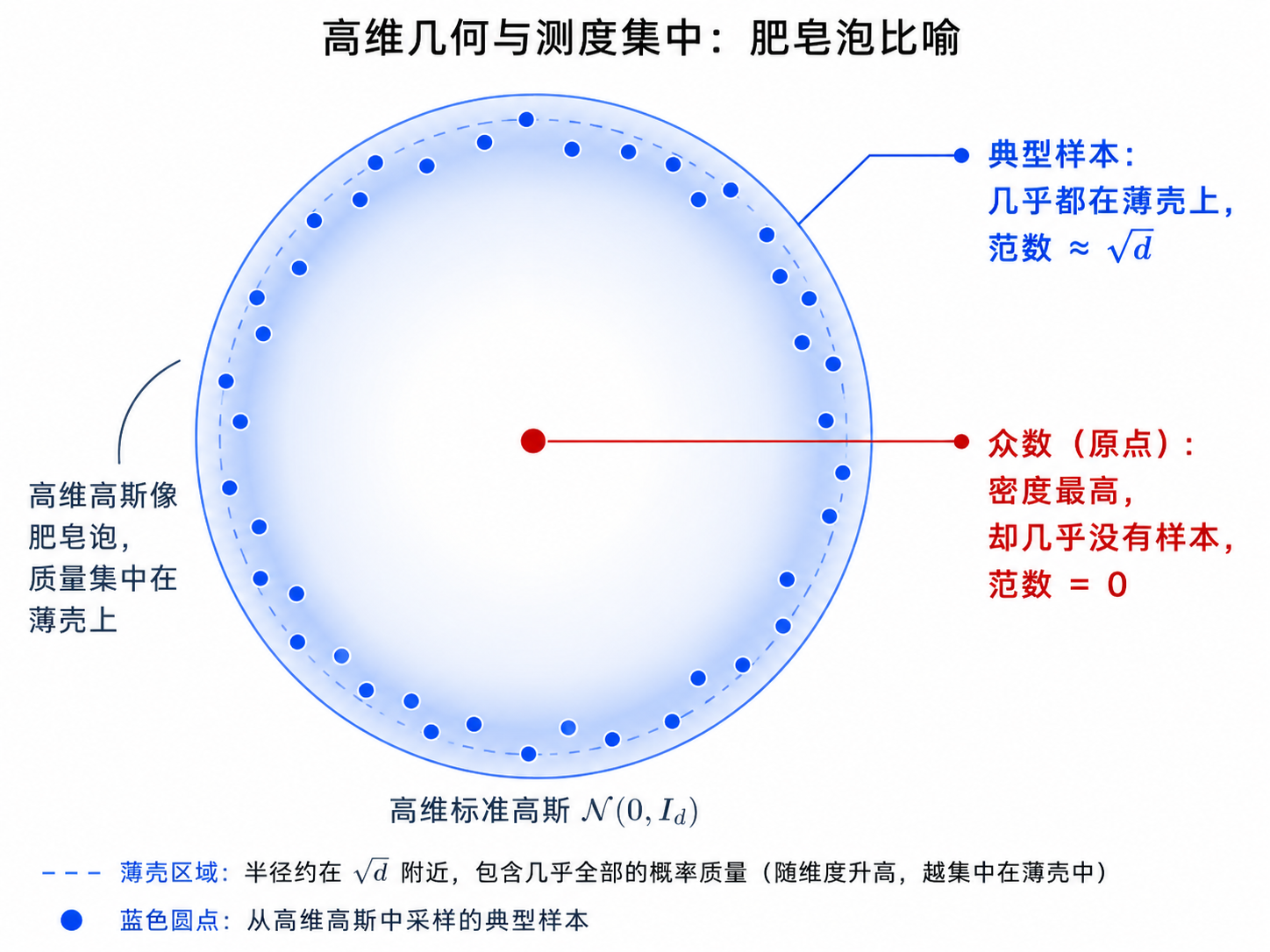
- 众数依赖表示:换个色彩空间/特征空间再做 MAP,答案可能就变了
- 测度集中:d 维高斯典型样本范数≈√d,而众数范数=0 → 众数高度非典型
- 所以纯 MAP 的"高概率"≠"看起来真实"
作者亲述 ▸ "肥皂泡"比喻正出自本文作者 Ferenc Huszár 的博客。这为把 AffGAN 扩展成从后验采样(变分推断)埋下伏笔。
AffGAN · 批评与反思30
为何 AffDG / AffLL 收敛却模糊?
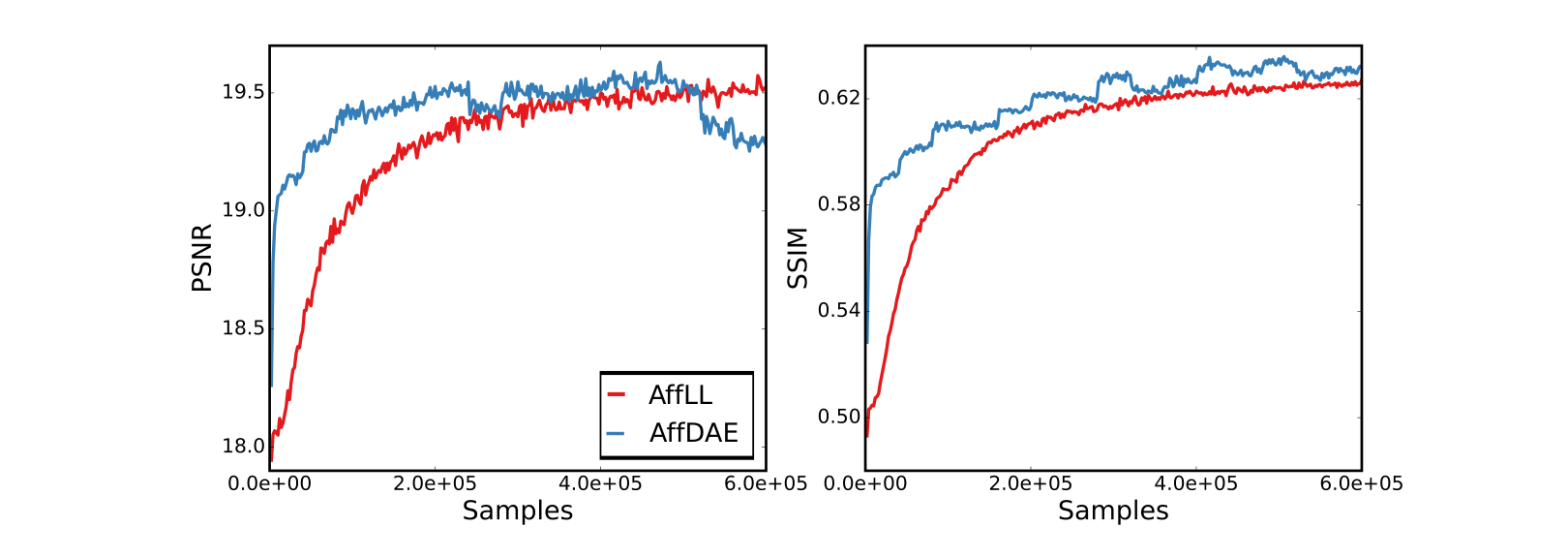
- 两模型都会收敛,但生成的图像很模糊(见 Fig 3)
- AffDG:高噪 σ 梯度方向粗但覆盖广,低噪 σ 梯度准但范围窄 → 需退火,仍易发散
- AffLL:精确密度模型在数据流形附近过于陡峭,早期学习极难
- 密度模型本身已不错(−4.10 bits/dim),但不够精确到能给出好的分数
结论 ▸ 这解释了为何在高维真实图像上,AffGAN 仍是赢家。
AffGAN · 补充:AffDG/AffLL31
把 AffGAN 扩展为摊销变分推断

给生成器额外输入噪声变量 z,让它能对同一个 x 产生多个合理 HR 解:
ŷ = ΠxA fθ(x, z)
\[ \operatorname*{argmin}_{\theta}\,\mathrm{KL}[q_{Y;\theta}\,\|\,p_Y]=\operatorname*{argmin}_{\theta}\,\mathbb{E}_{x}\,\mathrm{KL}[q_{Y\mid X;\theta}\,\|\,p_{Y\mid X}] \]
随机版 AffGAN ≈ 在执行摊销变分推断(如 VAE)
闭环 ▸ 这正好回应 §5.6 的批评——从后验采样而非死磕单个众数,与开头 Pixel Recursive SR 的"采样"思想殊途同归。
AffGAN · 变分推断视角32
一页回顾:MAP → 交叉熵 → 投影 → GAN
与 PRSR 的呼应 ▸ PRSR 显式建分布并逐像素采样;AffGAN 不显式建分布、前馈一次出图找众数。§5.6 + 附录 F 又把两条路汇合到“从后验采样”。
AffGAN · 总结33